














【本期看点】
- Hadoop和Spark框架的性能优化系统。
- 云计算重复数据删除技术降低冗余度。
- 压缩框架Ares如何统一不同算法。
- 在线数据压缩“摇摆门趋势”。
- 揭秘新型移动云存储SDM。
【技术DNA】
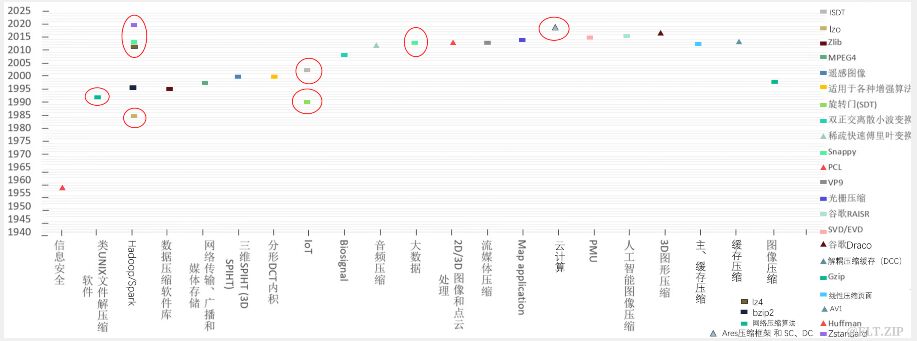
【智慧场景】
背景介绍
大数据概念
大数据(Big Data),又称为巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理的时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
但大数据是个抽象的概念,业界对大数据还没有一个统一的定义,而且用上面的定义似乎难以理解,所以就有了以下用 “4V” 来定义大数据的方法。
大数据特征
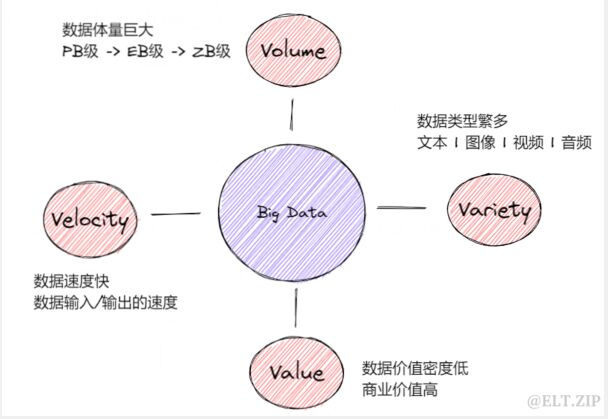
说到大数据的特征,就不得不提到“4V”。那什么是“4V”呢?
“4V” 即四个用来描述大数据特征的英文单词:Volume(体积)、Velocity(速度)、Variety(多样) 和 Value(价值)。用“4V”的方式给大数据下个中文定义,那就是满足数据体量巨大、数据速度快速、数据种类繁多和数据价值密度低的数据即大数据。
每天大家都在使用微信、QQ与好友开黑聊天,用支付宝、淘宝完成线上下支付。时过境迁,目前互联网产生的数据已经远远地超过很多年前的“3G时代”。比如下图,生动形象地描述了2021年各大互联网公司每分钟所产生的数据。
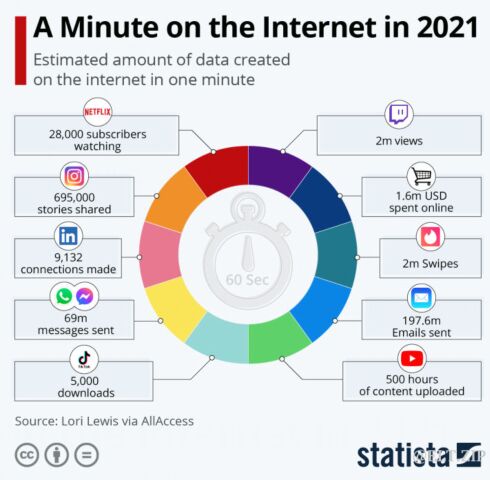
像是 Tiktok 每分钟就产生了5000次下载,197.6 百万条电子邮件被发出,500 个小时的视频被上传。虽然不是国内的数据,但也能反映出国内的一些情况,更能让我们体会到大数据时代下的数据量之大,数据种类之繁杂。侧面也能反映出处理这些数据的困难。
问题解决
那么大数据是怎样一步步发展到今天的呢?在回答这个问题之前,我们先来介绍一下两个由著名的 Apache 基金会开源出来的非常重要的项目 Apache Spark 和 Apache Hadoop。
Apache Hadoop 介绍
Apache Hadoop 是一个开源的,可靠的,可扩展的分布式计算框架,是下面这位大佬 Doug Cutting 发明的。这个项目的名称以及Logo来源也很有趣,就是大佬手中拿着的玩具的名字,对比一下 Apache Hadoop 的 Logo,是不是感觉有异曲同工之处?

Apache Hadoop 能做些什么呢?搭建大型的数据仓库以及PB级别的数据的存储、处理、分析、统计等业务,这些 Hadoop 都不在话下。而且,在搜索引擎时代,数据仓库时代、数据挖掘时代以及如今的机器学习时代,Hadoop 都分别担当着重要的作用。
Apache Spark 介绍
Apache Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架。具有运行速度快、易用性好、通用性强以及随处运行的特点。

Apache Spark 支持使用内存中处理来提升大数据分析应用程序的性能。 大数据解决方案旨在处理对传统数据库来说太大或太复杂的数据,而使用Spark处理内存中的大量数据,会比基于磁盘的替代方法要快得多。
两者的联系
Apache Hadoop 提供分布式数据存储功能HDFS,还提供了用于数据处理的 MapReduce。虽然 MapReduce 是可以不依靠 Apache Spark 进行数据的处理,Apache Spark 也可以不依靠 HDFS 来完成数据存储功能,但如果两者结合在一起,让 Apache Hadoop 来提供分布式集群和分布式 文件系统,Apache Spark 可以依附 HDFS 来代替 MapReduce 去弥补 MapReduce 计算能力不足的问题。
或许,有了上面的两个框架,处理如今的大数据时代所产生的问题已经很完美了,但是看一看下图对全球数据量以及其增速的预测,就能感觉到终有一天,现有的技术不能再满足我们,我们的技术仍然需要精进。
如何精进
从Hadoop源头
此时,或许我们应该了解一下 Apache Hadoop 的来源。Apache Hadoop 最早起源于Nutch。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003~2014 年 Google 发表的三篇论文为这个问题带来了解决的方案。三篇论文中分别提到了三个至关重要的技术点 GFS,MapReduce 以及 BigTable。最终分别演变成了 Hadoop 生态中的 HDFS,Hadoop MapReduce 以及 HBase。
- GFS:Google File System,Google的分布式文件系统。
- MapReduce:Google的分布式计算模型,用于解决PageRank问题。
- BigTable:列式存储Hbse的理论基础。
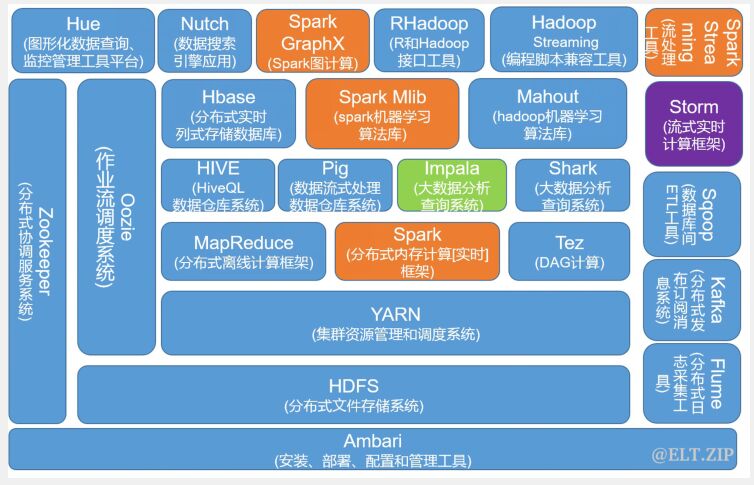
而其中的 Hadoop MapReduce 就是 Apache Hadoop 中重要的组成部分之一,它是数据中心的一个重要的数据处理引擎,它可以帮助用户避免维护物理基础设施的成本。许多研究都集中在 MapReduce 的任务上,来提高数据中心的性能并将能源的消耗大幅降低。这期阅读的论文也是研究了与 MapReduce 相关的数据压缩。
从数据压缩入手
数据压缩算法的权衡取决于各种因素,比如压缩程度、数据质量、压缩算法类型或者数据类型。最终的数据大小或是 I/O 减少的程度取决于压缩比,而压缩比取决于数据和压缩算法。这意味着更低的比率将会减少内存以及I/O的使用。
从Hadoop特性
下面是 Hadoop 中可用的压缩格式的摘要:
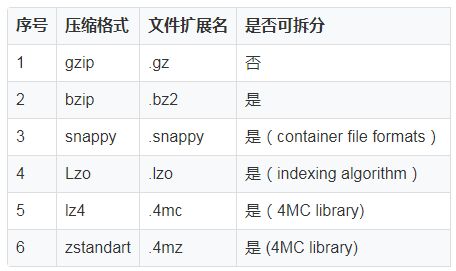
由于数据需要被安全的存储,所以作者选择的上表中所有选择的压缩编码器以及解码器都是无损的。
gzip 和 deflate 编解码器都使用 deflate 算法来替代 lz77 和 Huffman 编码的组合。两者的区别在于 Huffman 编码阶段
可拆分压缩 bzip2 编解码器使用 Burrows-Wheeler(块排序)文本压缩和 Huffman 编码算法。Bzip2 可以独立压缩数据块,也可以并行压缩数据块。
Snappy 是一个快速的数据压缩和解压缩库,使用了 lz77 的思想。Snappy 块是不可分割的,但是 Snappy 块中的文件是可分割的。
lzo (Lempel- Ziv-Oberhumer)压缩算法是 lz77 压缩算法的变体。该算法分为查找匹配,写入未匹配的文字数据,确定匹配的长度,以及写入匹配令牌部分。
压缩的数据文件由 lz4 序列组成,该序列包含一个标记、文字长度、偏移量和匹配长度。
Zstandart 是 Facebook 开发的一种基于 lz77 的算法,支持字典、大规模搜索框和使用有限状态熵和霍夫曼编码的熵编码步骤。
Hadoop 支持的压缩格式太多,因此需要一种可以动态选择压缩方式的算法,根据数据类型对压缩格式进行选择。
相关工作
- 关于 I/O 性能。作者分析了几篇论文,找到提升 I/O 性能并能提高能源效率的方法。
- 首先作者阅读量三篇论文,该论文中的作者将 4 个计算机节点集群,来研究部分数据压缩对 MapReduce 小工作量的情况下对性能的提高以及对能源的利用情况。
- 其次该论文中的作者从已有的几种方法和压缩算法来确定压缩方法,以减少数据加载时间和提高并发性。
- 最后,该论文中的作者研究了两种可动态选择的算法,通过周期性的压缩算法特征分析和实时系统资源状态的监控来实现最佳的 I/O 性能。
- 关于能源效率。作者选取了几篇论文,分析了不同的能源模型来预测 MapReduce 作业时的能源消耗。
- 通过调整数据复制系数和数据块大小参数,最小化了作业的执行时间和能耗。
- 其次,作者通过另一篇论文的一个预测 MapReduce 工作负载能耗的线性回归模型,发现了了通过精确的资源分配和只能的动态电压和频率缩放调度,可以显著节省能源。
- 还有,作者了解了修改 Hadoop 以实现可操作集群规模缩减方面的早期工作。
- 最后,作者阅读了一篇调整HPC集群并行度,网络带宽以及电源管理功能的策略,来达到高效执行 MapReduce 的目的。
- 作者最终通过修改Hadoop/Spark 框架中关于能源效率的各种配置参数,以达到提升 Hadoop MapReduce 作业的性能的目的。论文旨在提出一个选择最佳压缩工具并调整压缩因子以达到最佳性能的系统。
测试方法
方法框架
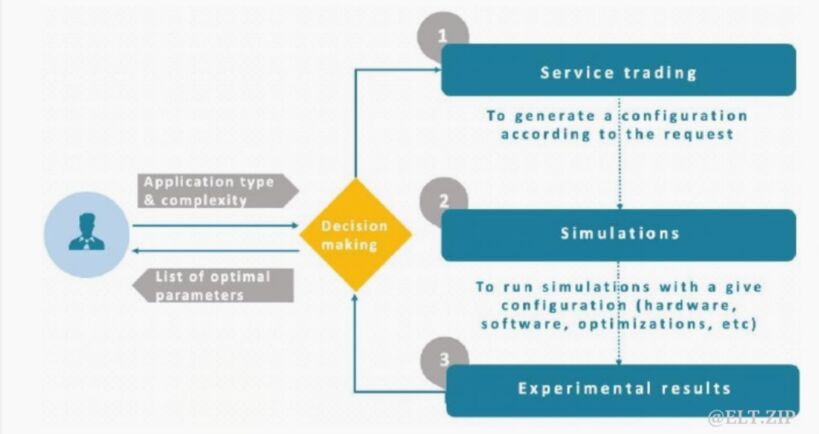
研究人员通过研究节省 CPU 和节省 I/O 之间的权衡,以此评估使用基于压缩工具的 Hadoop 和 Spark 框架下的大数据应用程序运行效率,并进一步调整压缩因子。同时,性能优化方法允许用户探索和优化大数据应用。下图为测试方法框架:
分布式I/O基准测试工具
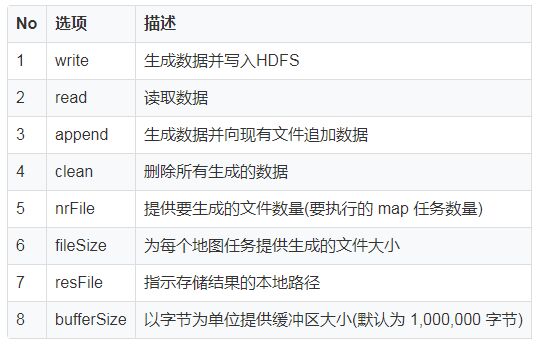
决策服务通过 REST API 将应用类型和复杂度发送给服务交易模块,以选择最优配置。在模拟模块中研究和实现了几个 MapReduce 类型的基准、工具和应用程序。作为分布式 I/O 基准测试工具,TestDFSIO 基准测试用于对 HDFS 进行压力测试并确定集群 I/O 速度。 TestDFSIO 对于识别网络瓶颈和强调集群节点上的硬件、操作系统和 Spark/Hadoop 配置也是必不可少的。 TestDFSIO 10 使用单独的 Map 任务(或 Spark 作业)执行并行读取和写入批量数据。在 Reduce 任务中收集统计信息以获取 HDFS 吞吐量和平均 I/O 的摘要。
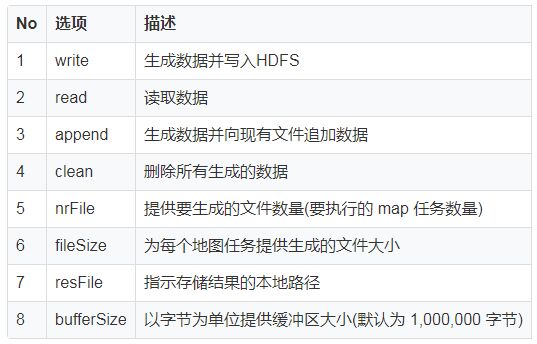
下表为TestDFSIO 选项摘要:
其他测试应用程序介绍
大量的 MapReduce 应用程序可以用于测试 HDFS 和 MapReduce 两层。
Terasort 包用于检查 HDFS 和 MapReduce 层,包括用于生成数据的 TeraGen、用于排序数据的 Terasort 和用于验证数据排序的 TeraValidate。 TeraGen 旨在生成大量数据,这是 TeraSort 的输入。生成数据的大小和输出是输入参数。 Terasort 对 TeraGen 生成的数据进行排序。 TeraValidate 检查排序后的 TeraSort 输出。输入和输出路径是 TeraSort 和 TeraValidate 基准参数。
WordCount 工作负载读取文本文件并计算找到单词的频率。 LogAnalyzer 工作负载读取日志文件作为输入,检测与输入的正则表达式匹配的行,并输出一个报告,通知关键字是否存在以及是否存在多少次。
测试用算法
聚类数据分析技术根据相似性度量将整个数据分组。 k-Means 聚类是数据科学中最简单、强大和流行的无监督机器学习算法之一 。已使用并行 k-Means MapReduce 应用程序,允许管理大型数据集以查找对象之间的距离。
评估内容与指标
输入数据使用背景部分中描述的压缩算法进行压缩。在 Hadoop 和 Spark 环境指标中评估三种类型的输入数据、七种压缩算法和五种工作负载(TestDFSIO、TeraSort、WordCount、LogAnalyzer、k-Means),以研究不同工作负载的环境和压缩算法。
如下表格给出了具体评估指标:
实验验证
环境配置
使用由一个主节点和 16 个从节点组成的 Hadoop/Spark 集群进行实验,具有如下不同的配置:1+4、1+8 和 1+16。
集群中的每个节点运行 Openstack 中间件,每个节点使用一个虚拟机,使用 Ubuntu 服务器 18.04 操作系统、3 GB 内存和 120 GB SATA 共享硬盘。
使用 Hadoop 版本 3.2.1、Spark 版本 2.4.5、Java JDK 版本 1.8 和 HDFS 块大小 128 MB。复制因子设置为2(默认值为3),方便数据节点的下线。每个 Apache Hadoop 和 Spark 环境的实验总数为 240。
压缩文件与原始文件的压缩率分析
所有实验均执行 4 GB、8 GB 和 16 GB 数据工作负载。数据压缩减少了存储使用量。压缩和原始文件压缩率的分析如下图所示。
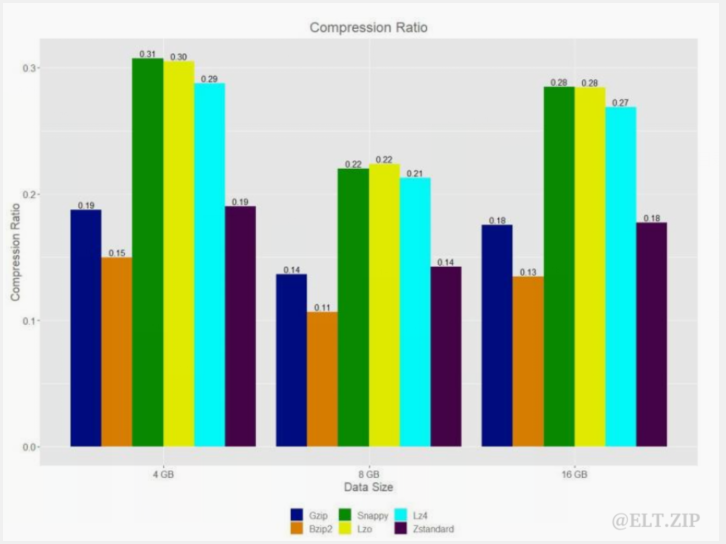
从上图我们可以得出具有最佳压缩率的算法为,Gzip、Zstandard 和 Bzip2 算法,其平均值为 13-17%。 gzip 和 bzip2 的压缩比差异约为 4%。根据基准,Gzip 的执行时间大约比 Bzip2 压缩快 7 倍。 Lzo、Lz4 和 Snappy 算法的压缩率低 26-27%,执行时间比 Gzip 压缩快约 7 倍,关于执行时间的介绍在下一部分。
LogAnalyzer 实验
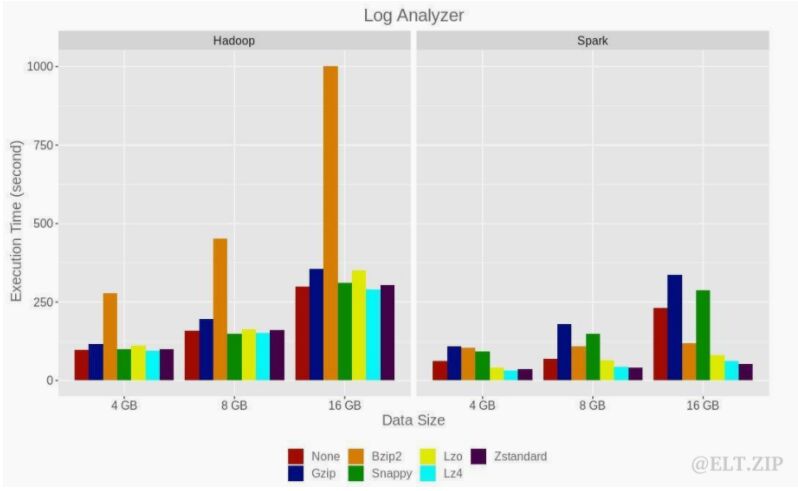
该实验的显示结果为,使用 lz4 压缩格式的 Spark,以及 8 GB 和 16 GB 数据集,对于未压缩的输入数据,以 15-25%和 18-28%的内存占用为代价,改进了 47%; 对可拆分的压缩数据占用 20-70%的 CPU 和 18-20%的内存;不可分割压缩数据的 CPU 占用率为 8-10%,内存占用率为 14-28%
无论输入数据大小如何,使用 lz4 压缩格式,LogAnalyzer 在 Hadoop 上的执行时间优化了 4.4%。 对于 Hadoop, 8节点和4节点配置的标准差为 2%,对于Spark, 8 节点配置的标准差为 9%,4 节点配置的标准差为 27%。Hadoop 集群中所有节点的平均 CPU 占用 率为 6-6.5%,内存占用率为 12-16.5%。在 Spark 上,对于未压缩的输入数据, 平均 CPU 占用为 15-25%和 18-28%;对于可拆分的压缩数据,平均 CPU 占用为 20-70%和 18-20%;对于不可拆分的压缩数据,平均 CPU 占用为 8-10%和 14- 28%。在 Hadoop 上,平均资源使用几乎是相同的。
LogAnalyzer 实验在 16 个节点 Hadoop 和 Spark 配置上对4GB、8GB和16GB 数据量执行时间对比如下:
WordCount 实验
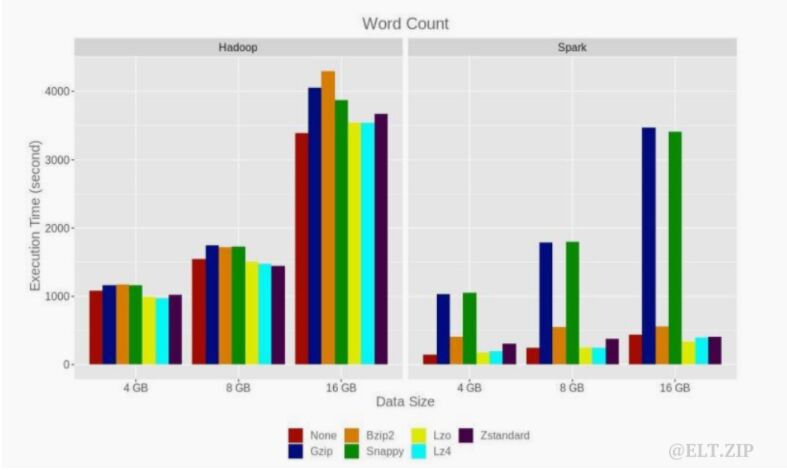
研究 WordCount 大规模仿真应用程序时,情况会有所不同。实验表明,在使用 16 GB 输入数据的情况下,压缩编解码器略微提高了 Hadoop 框架的执行时间。 Lz4 和 Lzo 编解码器在这两种情况下都表现出最佳性能。在 Hadoop 中,Lz4 的性能比 Lzo 稍高,而在 Spark 上则相反(Lzo 的执行时间较短)。8节点和 16节点配置的Hadoop执行时间几乎相同,但在 4 节点上,平均执行时间增加了 1.4%。在 Spark 8 节点集群上,平均执行时间增加了 17%,在四节点集群上增加了 51%。在 Hadoop 集群上,平均CPU使用率为 5.3-6.7%,内存使用率为 12-17.3%。在输入数据未压缩的 Spark 集群上,CPU 使用率为 20-47%,内存为 30-42%。对于使用不可拆分编解码器压缩的输入数据,平均 CPU 使用率为 6-7%,内存为 2030%,对于使用可拆分编解码器压缩的数据,CPU 为 20-50%,内存为 30-70%。作为 Hadoop 环境中 WordCount 作业的 LogAnalyzer,平均资源使用率几乎相同。 Wordcount 作业的最佳性能显示为Lzo 编解码器,比未压缩数据快 8%,但平均多使用 12% 的 CPU 和 23% 的内存。
16 个节点 Hadoop 和 Spark 配置上 4 GB、8 GB 和 16 GB 数据的 WordCount 实验性能对比如下:
TestDFSIO实验
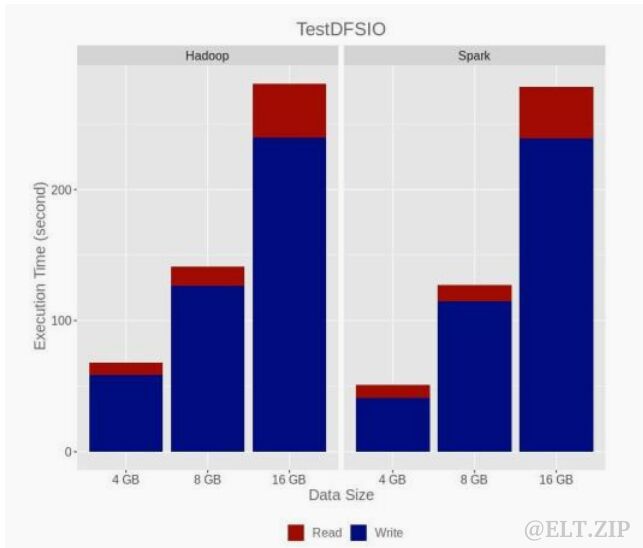
实验表明,除了适用于 Hadoop 集群的 Bzip2 慢速压缩算法外,可拆分编解码器还提高了LogAnalyzer 和 WordCount 应用程序的执行时间。
Gzip 和 Snappy 不可拆分编解码器减少了存储大小但增加了执行时间。
可拆分压缩编解码器对 Spark 环境有重大影响。压缩编解码器未用于 TeraGen 和 TestDFSIO 基准测试,因为算法人工生成数据的。
下图显示了 TestDFSIO 基准测试在具有 16 个节点配置的 Hadoop 和 Spark 环境中的执行时间:
TeraSort实验
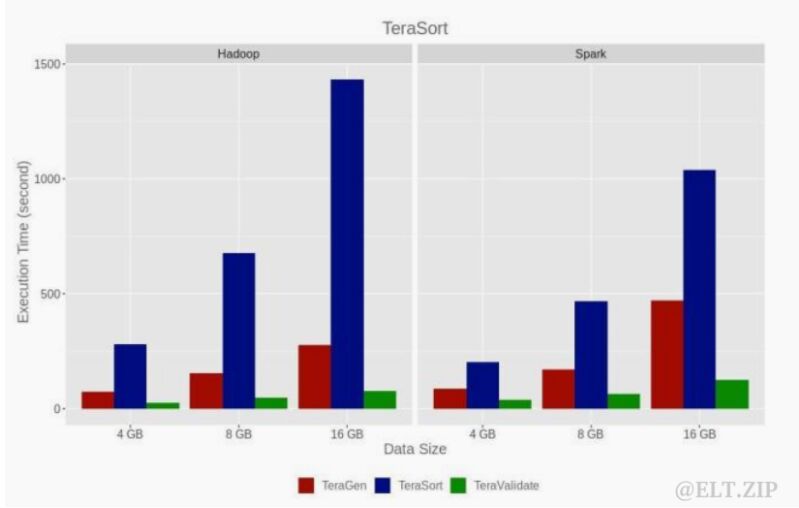
在 8 个节点的配置下,带有写选项的集群基准测试工作时间大致相同。 Hadoop的偏差为 2%,Spark 为 1%。读取选项的执行时间在 Hadoop 上增加了 82%,在Spark上增加了 31%。在四节点配置上,写入在 Hadoop 上慢 4%,在Spark上慢 18%,14 用于读取选项在两种环境下都慢三倍。图 6 显示了 TeraGen、TeraSort、TeraValidate 基准测试在具有 16 个节点配置的 Hadoop 和 Spark 环境中的执行时间。 TeraGen 和 TeraValidate 在 Hadoop 上工作得更快,在 Spark 上工作得更快。与Hadoop 相比,Spark 的基准测试模拟时间平均缩短了 12%。在八节点 Hadoop 和Spark集群上,TeraGen 和 TeraSort 的结果几乎相同,只有 2% 的差异,但对于 TeraValidate,在Hadoop上的基准执行时间增加了 20%,在 Spark 上增加了 50%。在四个节点上,与 16 个节点配置相比,Hadoop 集群 TeraGen 平均快 13%,Terasort 3%,Teravalidate 慢 43%。在四个节点上,Spark 集群 TeraGen 快 7%,TeraSort 慢 4%,Teravalidate 慢 72%。在这两种环境中,平均 CPU 使用率为 5-7%,在 Hadoop 上内存为 12-14%,在 Spark 上为 15-16%。
16 个节点 Hadoop/Spark 上4GB、8GB 和16GB数据的TeraSort基准执行时间如下图:
k-means实验
在 k-Means 聚类应用程序中,1GB、2GB、4GB输入数据大小用于实验。根据下图,Gzip、Snappy 和 Zstandart 编解码器表现出与输入未压缩时几乎具有相同的性能。
16 个节点Hadoop/Spark上1GB、2GB和4GB数据的K-means基准执行时间如该图:
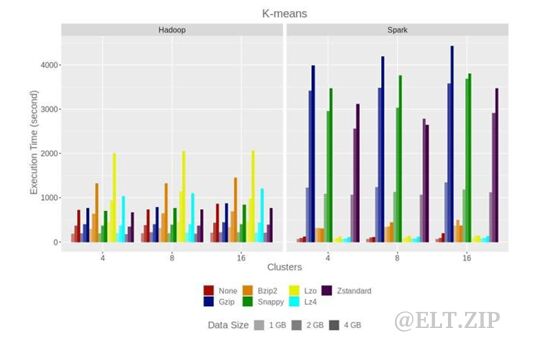
Spark 集群案例中的场景完全不同,因为除了Bzip2之外的可拆分编解码器显示出比未压缩数据更好的性能。通过具有大约 93% 的压缩比,使用 Lz4 编解码器可以达到最佳性能。而不是Hadoop(偏差为 1%),在 Spark 的四节点和八节点配置上,执行时间平均增加了 30% 和 93%。在Hadoop上,最佳性能显示 Zstandard 编解码器比未压缩数据快 6.4%。在Hadoop k-Means集群上,与 LogAnalyzer 和WordCount相比,平均资源使用率几乎相同。平均 CPU 使用率为 6-7%,而内存使用率为 16-18%。 Spark上性能最差的是Gzip、Zstandard和Snappy 编解码器,它们平均使用6-8% 的 CPU 和 30-48% 的内存。如果k-Means输入数据未压缩,则平均CPU使用率为 37-50%,而内存为 30-44%。在其他编解码器的情况下,平均CPU使用率为 11-56%,而内存为 26-44%。Spark 集群上的最佳性能显示 lz4,平均比未压缩的输入数据快 8.8%,但平均多使用 3% 的 CPU 和 1% 的内存。
内存和处理器使用情况的统计
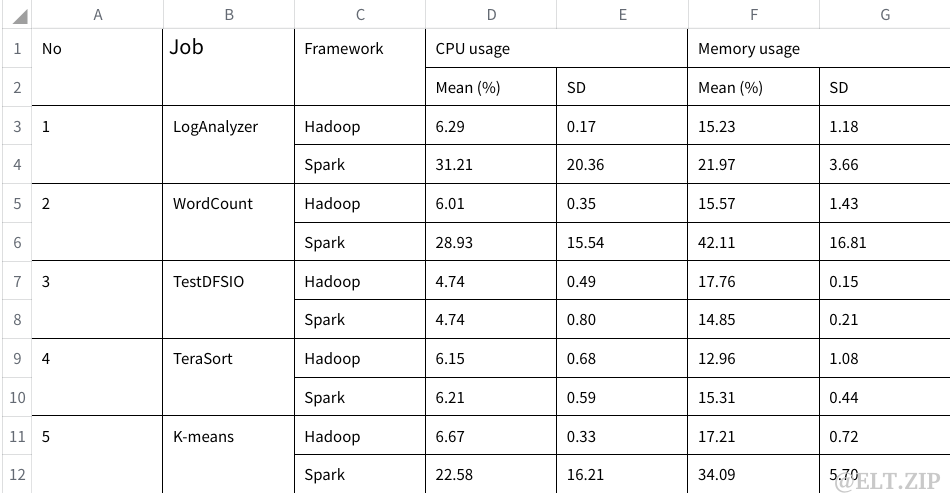
内存和处理器使用情况的统计分析如下表所示,以呈现数据的特征并研究分散性。在两种框架下 TestDFSIO 和 TeraSort 结果SD较小,结果可靠性高,但 LogAnalyzer、WordCount 和 k-Means 的数据和统计平均值之间存在较为明显的差异。
对五种工作负载的内存和处理器使用情况的均值和SD(标准差)分析如该表:
总结与最优解
本文的目的是为了能够找到最佳权衡以在 Apache Hadoop 和 Spark 框架中达到最佳性能的系统。上述文章在 Hadoop 和 Spark 环境中评估了适用于不同应用程序(包括 TestDFSIO、TeraSort、WordCount、LogAnalyzer 和 K-means)的4GB、8GB和16GB 数据工作负载。建议的系统使用评估结果来选择最佳配置环境。
我们由压缩数据处理分析结果可得:
无论输入数据大小如何,Lz4 编解码器都能达到 Hadoop 的最佳性能。
Spark 使用 Lz4 仅能在 4Gb 的输入数据下获得最佳性能,使用 Zstandard 编解码器仅能在 8Gb 和 16Gb 的情况下可以获得最佳性能。































