在大数据的背景下,微软似乎并不像其他数据库厂商一样在高调宣传他们的大数据产品或解决方案。而在应对大数据挑战方面,倒是一些互联网巨头走在最前面,比如Google和Yahoo,前者每天都要处理20 PB的数据量,其中一大部分是基于文档的索引文件。当然,如此界定大数据是不准确的,它并不仅限于索引,企业中的电子邮件、文档、Web服务器日志、社交网络信息以及其他所有非结构化的数据库都是构成大数据的一部分。
为了应对这些数据的挑战,像Autodesk、IBM 、Facebook当然还包括Google和Yahoo,都毫无例外地部署了Apache Hadoop开源平台。微软也注意到这一趋势,所以在他们的数据库平台中添加了Hadoop连接器。该连接器可以让企业将海量的数据在Hadoop集群和SQL Server 2008 R2、并行数据仓库以及***的SQL Server 2012(Denali)之间进行自由的移动。由于连接器可以让数据双向移动,所以用户不仅可以利用SQL Server所提供的强大的存储以及数据处理功能,还可以用Hadoop来管理海量的非结构化数据集。
但是传统的微软用户对于SQL Server Hadoop连接器还比较陌生,使用起来会很不习惯。该连接器是一个部署在Linux环境中的命令行工具,在本文中,我们就将为您具体讲解一下SQL Server Hadoop连接器的工作原理。
Apache Hadoop集群
Hadoop是一个主-从架构,部署在Linux主机的集群中。想要处理海量数据,Hadoop环境中必须包含一下组件:
- 主节点管理从节点,主要涉及处理、管理和访问数据文件。当外部应用对Hadoop环境发送作业请求时,主节点还要作为主接入点。
- 命名节点运行NameNode后台程序,管理Hadoop分布式文件系统(HDFS)的命名空间并控制数据文件的访问。该节点支持以下操作,如打开、关闭、重命名以及界定如何映射数据块。在小型环境中,命名节点可以同主节点部署在同一台服务器上。
- 每一个从节点都运行DataNode后台程序,管理数据文件的存储并处理文件的读写请求。从节点由标准硬件组成,该硬件相对便宜,随时可用。可以在上千台计算机上运行并行操作。
下图给出了Hadoop环境中各个组件的相互关系。注意主节点运行JobTracker程序,每个从节点运行TaskTracker程序。JobTracker用来处理客户端应用的请求,并将其分配到不同的TaskTracker实例上。当它从JobTracker那里接收到指令之后,TaskTracker将同DataNode程序一同运行分配到的任务,并处理每个操作阶段中的数据移动。
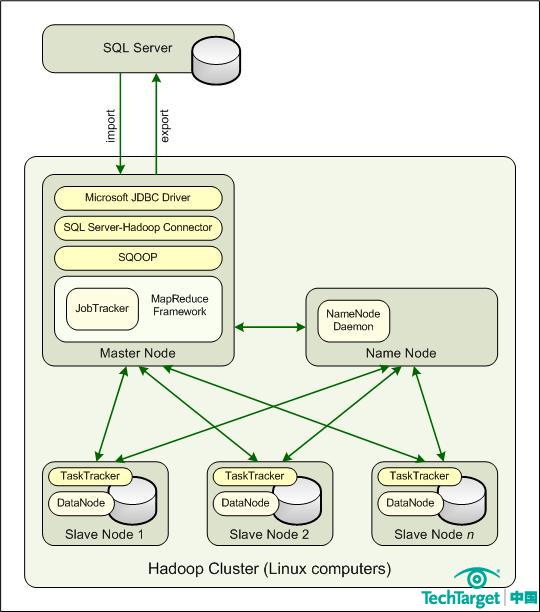
你必须将SQL Server Hadoop连接器部署在Hadoop集群之内
MapReduce框架
再如上图所示,主节点支持MapReduce框架,这一技术是依赖于Hadoop环境之上的。事实上,你可以把Hadoop想象成一个MapReduce框架,而这个框架中会有JobTracker和TaskTracker来扮演关键的角色。
MapReduce将大型的数据集打散成小型的、可管理的数据块,并分布到上千台主机当中。它还包含一系列的机制,可以用来运行大量的并行操作,搜索PB级别的数据,管理复杂的客户端请求并对数据进行深度的分析。此外,MapReduce还提供负载平衡以及容错功能,保证操作能够迅速并准确地完成。
MapReduce和HDFS架构是紧密结合在一起的,后者将每个文件存储为数据块的序列。数据块是跨集群复制的,除了***的数据块,文件中的其他数据块大小都相同。每一个从节点的DataNode程序会同HDFS一起创建、删除并复制数据块。然而,一个HDFS文件只可以被写一次。
SQL Server Hadoop连接器
用户需要将SQL Server Hadoop连接器部署到Hadoop集群的主节点上。主节点还需要安装Sqoop和微软的Java数据库连接驱动。Sqoop是一个开源命令行工具,用来从关系型数据库导入数据,并使用Hadoop MapReduce框架进行数据转换,然后将数据重新导回数据库当中。
当SQL Server Hadoop连接器部署完毕之后,你可以使用Sqoop来导入导出SQL Server数据。注意,Sqoop和连接器是在一个Hadoop的集中视图下进行操作的,这意味着当你使用Sqoop导入数据的时候是从SQL Server数据库检索数据并添加到Hadoop环境中,而相反地,导出数据是指从Hadoop中检索数据并发送到SQL Server数据库当中。
Sqoop导入导出的数据支持一些存储类型:
- 文本文件:基础的文本文件,用逗号等相隔;
- 序列文件:二进制文件,包含序列化记录数据;
- Hive表:Hive数据仓库中的表,这是针对Hadoop构建的一种特殊的数据仓库架构。
总体来说,SQL Server和Hadoop环境(MapReduce和HDFS)能够让用户处理海量的非结构化数据,并将这部分数据整合到一个结构化的环境中,进行报表制作以及BI分析。
微软大数据策略才刚刚开始
SQL Server Hadoop连接器在微软大数据之路上算是迈出了重要的一步。但与此同时,由于Hadoop、Linux和Sqoop都是开源技术,这意味着微软要对开源世界大规模地敞开胸怀。其实微软的计划并不只如此,在今年年底,他们还将推出一个类似于Hadoop的解决方案,并以服务的形式运行在Windows Azure云平台上。
在明年,微软还计划推出针对Windows Server平台的类似服务。不能否认,SQL Server Hadoop连接器对于微软来说意义重大,用户可以在SQL Server环境中处理大数据挑战,相信在未来他们还会带给我们更多的惊喜。
【编辑推荐】