大家都知道函数调用是通过栈来实现的,而且知道在栈中存放着该函数的局部变量。但是对于栈的实现细节可能不一定清楚。本文将介绍一下在Linux平台下函数栈是如何实现的。有些同学可能觉得没必要了解这么深入,其实非也。根据本号多年的经验,了解系统深层次的原理对分析疑难问题有很好的帮助。

图0 函数栈
就像熟悉抓包是解决网络通信问题的高级武器一样,熟悉函数调用栈则是分析程序内存问题的高级武器。本文以Linux 64位操作系统下C语言开发为例,介绍应用程序调用栈的实现原理,并通过一个实例和GDB工具具体分析一下某个程序的调用栈内容。在介绍具体的调用栈之前,我们先介绍一些基础知识,这些知识是理解后续函数调用栈的基础。
X86 CPU的寄存器
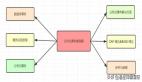
CPU的寄存器是需要了解的基础知识,这是因为在X64体系中函数的参数是通过寄存器传递的。如图1是X86 CPU寄存器的列表及功能简要说明。

图1 Intel X86 CPU寄存器用途
我们知道Intel的CPU在设计的时候都是向前兼容的,也就是在新一代的CPU上可以运行老一代CPU上的编译的程序。为了保证兼容性,新一代CPU保留了老一代寄存器的别名。以16位寄存器AX为例,AL表示低8位,AH表示高8位。而32位CPU问世之后,通过名为EAX的寄存器表示32位寄存器,AX仍然保留。以此类推,RAX表示一个64位寄存器。
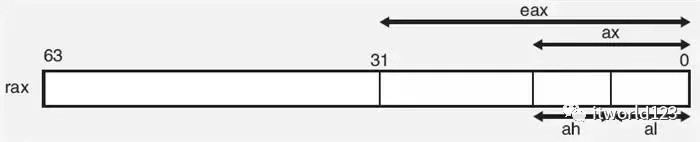
图2 不同的寄存器名称
应用程序的地址空间
操作系统通过虚拟内存的方式为所有应用程序提供了统一的内存映射地址。如图3所示,从上到下分别是用户栈、共享库内存、运行时堆和代码段。当然这个是一个大概的分段,实际分段比这个可能稍微复杂一些,但整个格局没有大变化。

图3 应用程序的地址空间
从图中可以看出用户栈是从上往下生长的。也就是用户栈会先占用高地址的空间,然后占用低地址空间。目前我们可以大体上有个了解即可,后面我们在详细分析用户栈的细节。
函数调用及汇编指令
为了理解函数调用栈的细节,有必要了解一下汇编程序中函数调用的实现。函数的调用主要分为2部分,一个是调用,另外一个是返回。在汇编语言中函数调用是通过call指令完成的,返回则是通过ret指令。
汇编语言的call指令相当于执行了2步操作,分别是,1)将当前的IP或CS和IP压入栈中; 2)跳转,类似与jmp指令。同样,ret指令也分2步,分别是,1)将栈中的地址弹出到IP寄存器;2)跳转执行后续指令。这个基本上就是函数调用的原理。
除了在代码间的跳动外,函数的调用往往还需要传递一个参数,而处理完成后还可能有返回值。这些数据的传递都是通过寄存器进行的。在函数调用之前通过上文介绍的寄存器存储参数,函数返回之前通过RAX寄存器(32位系统为EAX)存储返回结果。
另外一个比较重要的知识点是函数调用过程中与堆栈相关的寄存器RSP和RBP,两个寄存器主要实现对栈位置的记录,具体作用如下:
- RSP:栈指针寄存器(reextended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
- RBP:基址指针寄存器(reextended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
寄存器的名称跟体系结构是相关的,本文是64位系统,因此寄存器是RSP和RBP。如果是32位系统则寄存器的名称为ESP和EBP。
应用程序调用栈
我们先从整体上来看一下函数调用栈的主要内容,如图4所示。在函数栈中主要包括函数参数表、局部变量表、栈的基址和函数返回地址。这里栈的基址是上一个栈帧的基址,因为在本函数中需要使用该基址访问栈中的内容,因此需要首先将上一个栈帧中的基址压栈。

图4 函数调用栈概览
为了便于理解,我们以一个具体的程序作为示例。本程序非常简单,主要是模拟了多个函数的函数调用关系和参数传递。另外,在函数func_2中定义了2个形参,以模拟多参数传递的过程。

图5 函数栈汇编分析
在本示例中,main函数调用func_1函数。我们从main函数开始分析,可以先看一下右侧的C语言代码。首先是函数参数的准备过程。在main函数调用func_1时依次传入的参数为1、2、3和4+g,其中***一个参数是需要计算的。按照红色方框的虚线,我们可以看到对应的汇编程序,在汇编程序中首先处理***一个参数,然后是倒数第二个,以此类推(函数参数的处理顺序在日常开发中是需要注意的内容重点)。同时,我们看到存储参数的寄存器名称与前文是一致。
当准备完参数之后,就是调用func_1函数,这个在汇编语言中就是call func_1这一行。虽然只是一行汇编指令,但其实内部做了一些事情,这个我们在前文介绍call指令的时候有所介绍,大家可以参考一下前文。
之后就进入func_1函数的处理逻辑。最一开始是pushq %rbp汇编程序,这句指令的作用是将RBP压入函数栈中。这句压栈及后面的更新RBP的值(moveq %rsp, %rbp)是构建本函数的栈帧头,后续对本栈帧的内容的访问都是通过帧头(RBP)进行的。接下来是对参数压栈的过程和局部变量初始化的过程,具体分布参考图5中的绿色方框和红色方框。
完成函数内的运算后,***将运算结果放入寄存器EAX中,然后调用指令leave和ret。这里面需要说明的是leave指令,该指令相当于下面两条汇编指令。可以对比一下函数入口的汇编指令,其实两者是对称的。leave指令将本帧的栈基址赋值给栈指针(图6中步骤2),然后将其中的内容弹出到RBP中(图6中步骤3)。其实就是RBP指向上一个帧(调用者)的栈帧,也即是一个复原的过程。
- movl %ebp %esp
- popl %ebp
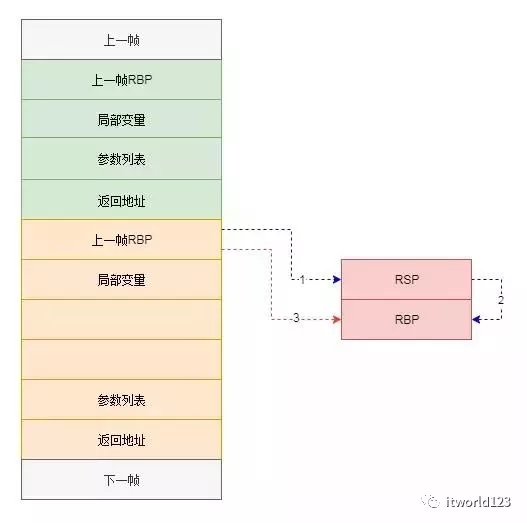
图6 函数返回示意图
这样,函数返回后寄存器RBP和RSP从被调用者的栈帧切换到了调用者的栈帧。
通过GDB分析函数调用栈
上面是通过反汇编的方式分析函数的调用栈和栈帧情况。我们还可以通过gdb动态的分析函数栈和栈帧的使用情况。我们依然通过main函数调用func_1函数为例来分析。我们这里在函数func_1的入口处设置一个单点,然后运行程序,程序停止在断点处。如图7是我们逐步执行是函数栈的变化过程,具体细节我们这里就不再赘述,大家可以实际操作一下。
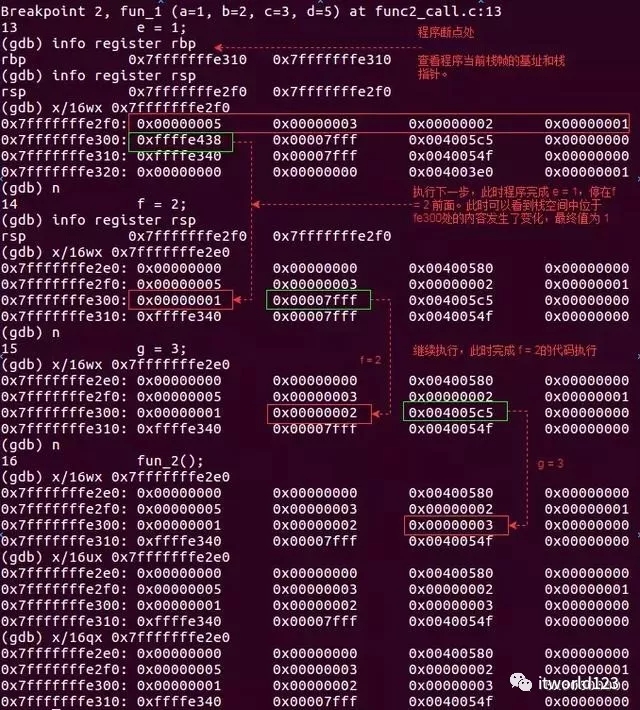
图7 函数栈变化过程
本文的目的是让大家对函数调用栈有个整体的了解,这样对以后程序的疑难杂症就有更多的解决思路。因为在实际生产环境中与栈相关的问题也是比较多的,比如局部变量太多导致的栈溢出,或者踩内存问题引起的栈破坏等等。因此,了解了函数栈的原理,在遇到所谓的莫名其妙问题的时候就会有新的思路。往往很多问题不是问题本身莫名其妙,而是我们的知识储备不够,自己感觉莫名其妙而已。