














大家好,我是百度运维部平台研发工程师颜志杰,毕业后一直在百度做运维平台开发,先后折腾过任务调度(CT)、名字服务(BNS)、监控(采集&计算);今天很高兴和大家一起分享下自己做“监控”过程中的一些感想和教训。
现在开始本次分享,本次分享的主题是《多维度数据监控采集&计算》,提纲如下,分为3个部分:
1.监控目标和挑战
2.多维度数据监控
2.1.采集的设计和挑战
2.2.聚合计算的设计和挑战
2.3.高可用性保障设计
3.总结&展望
首先进入***部分 :监控目标和挑战,先抛出问题,装装门面,拔高下分享的档次(个人理解,欢迎challenge)。
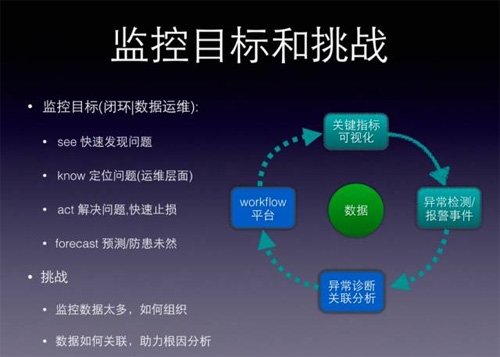
监控期望做到:快速发现问题,定位问题(运维层面),解决问题,甚至要先于问题发生之前,预测/防患未然,形成处理闭环,减少人工决策干预。
先解释一下“定位问题(优先运维层面)”,意思是站在运维角度“定义故障”,不需要定位到代码级别的异常,只需定位到哪种运维操作可以恢复故障即可,比如确定是变更引起的,则上线回滚,机房故障则切换流量等…
不是说监控不要定位到代码级别的问题,事情有轻重缓急,止损是***位,达到这个目标后,我们可以再往深去做。
再解释下“预测/防患未然”,很多人***反应是大数据挖掘,其实有不少点可以做,比如将变更分级发布和监控联动起来,分级发布后,关键指标按照“分级”的维度来展示。(记住“分级”维度,先卖个关子:)
“监控目标”这个话题太大,挑战多多。收敛一下,谈一下我们在做监控时,遇到的一些问题,挑两个大头,相信其他在大公司做监控的同学也有同感:
1.监控指标多,报警多
2.报警多而且有关联,如何从很多异常中找出“根因”
今天先抛出来两个头疼的问题,下面开始进入正题“多维度数据监控”,大家可以带着这两个问题听,看方案是否可以“缓解”这两个问题。
进入正题:
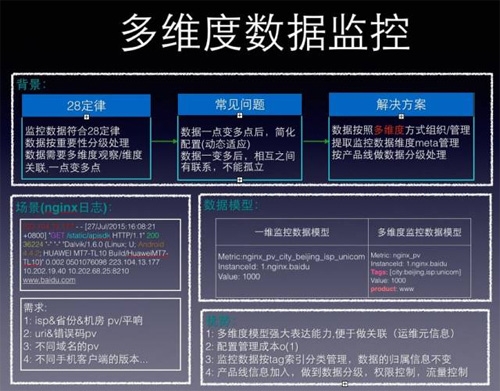
先看***个问题:监控数据多。监控数据符合28定律,“关键”和“次要”指标需要区别对待,不能以处理了多大数据量引以为傲,需要按重要性分级处理,将资源倾斜到重要数据上分析和处理。
#p#
监控一个服务,把精力放在那20%的关键指标数据上,80%的次要指标作为出问题后,分析根因所用,如何采集关键指标,留到采集一章,下面以百度某产品线接入服务为例来说明“关键”指标处理有怎样的需求。
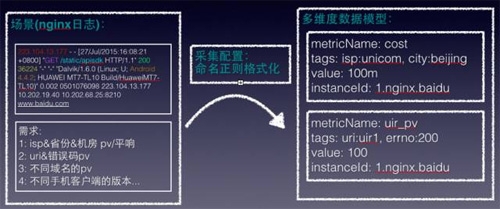
下面以百度地图产品线接入日志为例 (典型的nginx日志):
- 223.104.13.177 - - [27/Jul/2015:16:08:21+0800] "GET /static/apisdk HTTP/1.1" 200 36224 "-""-" "Dalvik/1.6.0 (Android 4.4.2; HUAWEI MT7)" 0.0020501076098 223.104.13.177 10.202.19.40 10.202.68.25:8210 www.baidu.com
百度地图接入服务需要有这些监控:按照运营商、省份、省份&运营商pv/平响;不同urihttp_code在不同机房pv/平响, 请求手机操作系统版本的pv…
可以看到,一个指标会变为多个指标,比如pv监控项按照 5大运营商*36个省份 * 5个机房将产生900个指标数据,人工管理这种配置很困难,而且如果新增机房,需要新增配置5*36=180个配置,这个就不是人干的了。
同时,这些指标之间是相互关联的,自然想知道地图pv数据,在哪几个运营商,省份,机房有数据,所以需要对监控项进行meta管理。
总结一下,“关键”指标数据需要多角度/多维度观察,会一点变多点,这些多点数据有关联,需要meta管理,简单配置,那么如何来解决呢?
数据模型先行*3(重要的事情说三遍),选择一个好的数据模型来组织监控数据,解决上面提到的问题,将会有不同的效果,下面是两种数据模型的优劣(也是我们自己的监控历程)。
贴一下图:

监控数据需要多角度观察,这是强需求,在一维数据模型中,将维度信息放在了监控项名字里面,比如nginx_pv_city_beijing_isp_unicom表示的是北京联通的pv,nginx_pv_city_beijing_isp_cmnet表示北京中国移动的pv。
这种数据模型,监控项间无关联,除非对名字做一系列规定,并增加对名字做split操作之类,否则很难让上面两个数据产生关联;而且配置的个数是维度的笛卡尔积。
参考aws的cloudwatch,有了多维度数据模型,通过tags来扩展维度,比如把运营商、省份放到tags字段里面,这样用一份配置产生900关联的监控数据;并加入了product字段,在数据分级,权限控制上有作用,后面再展开。
日志里面没有运营商和省份,机房信息,是如何获得的呢?这些我们统一叫做“运维元信息”,先卖个关子,待会在采集那一节展开,不过大家可以先有个印象,tags里面“维度”的取值可以做到很有“扩展性”。
所以结论是,监控数据符合28定律,重要数据需要多角度观察,会产生多个相关联数据,需要有meta管理,需要动态简单配置。多维度数据模型可以很好的解决这些问题,内部我们将处理这数据模型的监控叫“多维度数据监控”。
多维度数据监控在处理/资源消耗上没有减少,900个数据一个不少,所以我们将这套解决方案定位在处理“关键”数据,倾斜资源;而且只关注不同维度的聚合数据,单机数据在单机上存储即可,这都是基于资源的考虑。
铺垫了这么长,现在看看“多维度数据监控”的框架拆解:
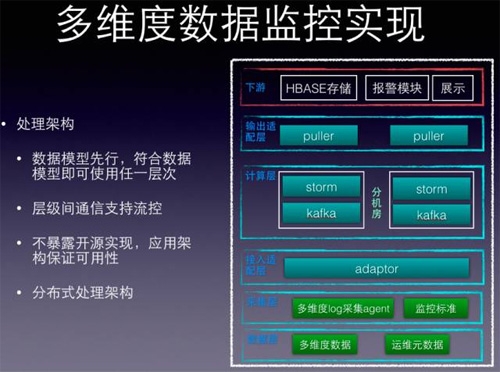
典型的分层处理架构,采集=>计算=>存储=>报警+展示,没什么特别说的,想要强调2点:
1.数据模型先行,任何的一个层级只要符合“多维度数据模型”都可以独立使用,每个层级都是服务化的。再强调一下“数据模型先行”。
2.聚合流式计算分布式架构,不暴露开源实现,开源之上都有适配层,很多的处理可以在适配层展开,这个好处在可用性章节具体展开。
下面开始依次介绍多维度采集&聚合计算&高可用性保证三个小节:
先介绍采集,如果大家对logstash熟悉那***,采集agent很多功能点都是借鉴logstash来写的,当然设计上有些改动,欢迎拍砖。
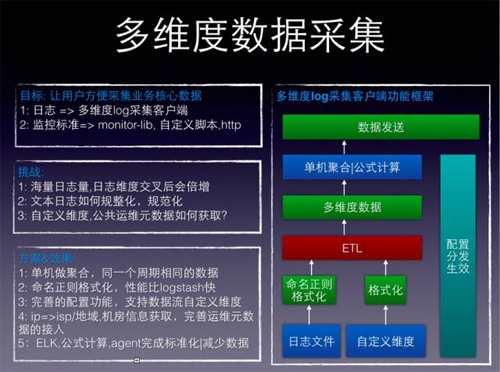
数据采集就是一个标准化的过程,服务以某种方式吐出数据,采集负责把数据转换为监控数据模型,发往下游处理;所以理想情况是推监控标准,服务链接监控lib,lib将服务核心指标吐过来。
理想我们在努力中,然而… 所以,目前,关键指标大部分通过日志来获取,遇到的挑战是:
1.日志量大=>不传原始日志,而且在agent做各种手段来减少数据传输。
2.日志如何规整化=>参考logstash,用命名正则来规整。
3.tags要做到很有‘扩展性’=> agent端需要支持对tag的自定义。
依次来说,***如何降低数据传输,首先单机会做聚合,即一个周期内(如10s),所有tags取值相同的监控会合成一条数据发送。比如百度地图接入服务中,10s内来自北京联通的请求变成一条监控数据,这个策略实践证明对于减少数据是很明显的。
数据减少手段还有ETL和公式计算,agent端就确定哪些数据是不用传递的,比如实现dict映射,只有在字典dict内的值才放行,其他的都归结到other里面。
比如,运营商其实有20+,但一般OP就关注4大运营商,所以可以通过dict将其他的运营商都归结到“other”里面,而且还支持重命名,既规整了tag的取值,又减少了数据的传递,比如有如下的dict:
- "dict": [
- "CHINANET => 电信",
- "UNICOM => 联通",
- "CMNET => 移动",
- "CRTC => 铁通"
- ]
#p#
公式计算也如此,尽早的过滤不需要的数据,我们支持四则,逻辑运算,当agent端具备这样的表达能力后,扩大了agent采集的能力,可以采集很多有意思的监控项:
比如根据nginx的响应时间${cost}和http错误码${errno},去定义损失pv,通过公式:${cost} > 2000 || ${errno} != 200 时间大于2s或errno不等于200,保证聚合计算功能纯碎性,降低数据传输量。
第二个问题,日志如何规整化,通过命名正则来格式化文本日志,我们用c++写的客户端性能较logstash快不少,这里强调一下,我们没有像logstash一样可以支持多个线程去做正则,只有一个线程来计算,这样做的考虑是:
正则匹配成功性能还可以,一般性能耗在不匹配的日志,出现不匹配的时候,正则会进行一些回溯算法之类的耗时操作,agent设计尽量少进入处理“不匹配日志”。
通过增加“前置匹配”功能,类似大家去grep日志的时候,“grep时间戳|grep–P ‘正则’ ”,字符串查找和正则匹配性能相差极大,agent端借鉴这个思想,通过指定字符串查找过滤,保证后面的日志基本都匹配成功,尽量避免进入“正则回溯”等耗时操作,在正确的地方解决问题。
这种设计保证agent最多占一个cpu。实践证明,通过“前置匹配”,保证进入正则日志基本匹配成功,几千qps毫无压力,而且一般只占一个cpu核30%下。
第三个问题,Tag扩展性,tag是整个多维度监控的精髓,首先我们支持用户自定义任何tag属性,有统一的接口提供,你可以对监控数据上定义任何的tag,比如搜索服务里面可以加上库层属性。
前面提到的运营商、省份,这个通过在agent端用一个ip库来实现反解,当然ip库更新是一个问题,目前随着agent的升级来进行更新,时效性不高。大家可以考下为何不放在server端处理:)
日志采集agent通过上面的一些手段,基本满足了在关键指标的采集上的要求,完成了“标准化”,数据“精简化”的需求。
总结一下,日志采集就是标准化的过程,通过采集配置将日志里面的信息变成多维度的数据模型,发送给后端模块处理。
跟logstash比,想强调前置匹配功能点,没有借鉴其多线程处理的设计,坚持单线程处理,如果监控需要消耗太多的资源去达到,那么我就对这个合理性存疑了。
采集就介绍到这,下面开始介绍实时汇聚计算。
前面提到,多维度数据监控不关注“单机”数据,只关注聚合数据,那首先***个问题,怎么圈定“聚合"范围?这块功能在名字服务中实现,名字服务不展开。
如上图,通过名字服务完成聚合范围的圈定,支持三级范围圈定(实例id=>服务=>服务组),一个机器上的模块称为实例,实例发送的数据就是刚刚上面讲的采集agent发出来的,每个数据都带一个id标示,称为实例id。
范围圈定后,通过指定聚合规则,我们拼成一个聚合所需要的数据结构,这个数据是自包含的,即监控数据+聚合规则都包括在里面,如下图所示:
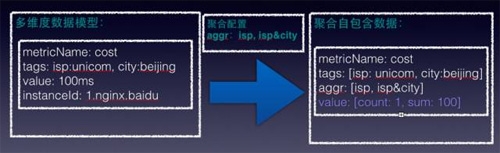
将多维度数据+聚合配置变成聚合自包含数据,自包含数据包含了怎么对这个数据进行计算,上面标示要按照isp运营商汇聚,以及按照运营商和城市来汇聚。
有了聚合自包含数据后,就开始进行汇聚计算,如下图所示:
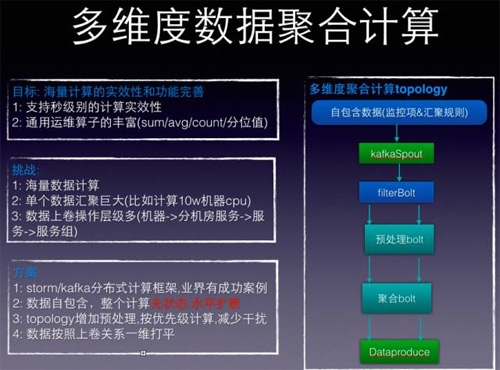
首先我们只支持一些特定的运维算子,计算count、sum、avg、分位值、min/max基本上能涵盖运维的需求,比如count就是pv,sum/avg/分位值算平响等。
遇到的挑战包括:
1.单个汇聚的数据量过大,比如要计算10w机器的cpu_idle,最终需要要按照filed去累加,过大数据缓存累加,容易OOM,这个需要考虑storm的算子设计。
2.数据范围的圈定是支持三层,也就是数据上卷操作如何来支持。
先来看***个问题,介绍storm算子的设计,大家看下图:
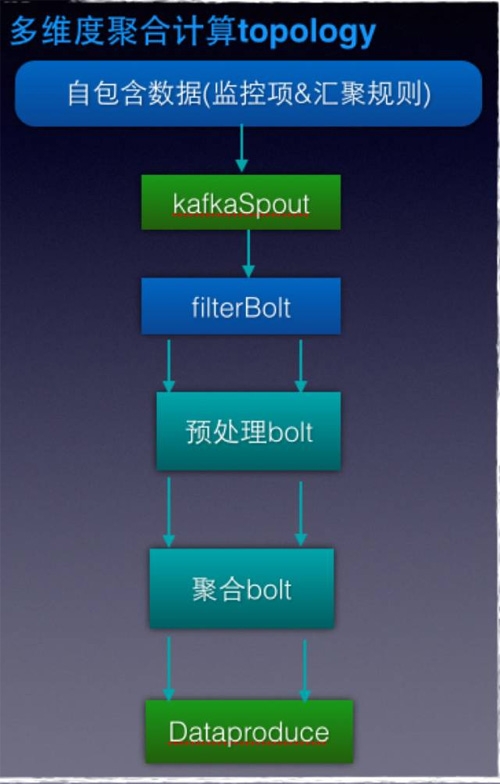
整个topology做到了无状态,处理的数据是自包含,其次计算加了一层预处理bolt,先用shuffer来处理一层,降低field到聚合bolt的计算量。比如计算10w机器的10s 钟cpu_idle(1wqps)先用10个预处理bolt,每个bolt就是只要累加1/10的数据,然后到下一层的计算量就会较小了。
#p#
算子可以这么设计是因为计算avg不受影响,avg=sum/count,把10s sum加起来,和先加2s的sum,然后2s中间结果再加起来,除以count,精度没有损失,但分位值有精度损失,这个需要权衡。
storm算子设计就介绍到这,下面开始介绍数据上卷操作。
数据上卷在接入层做数据一维打平,在接入层的时候按照名字服务的圈定范围变成了多份自包含数据,比如实例1=>服务2=>服务组3,那么来自实例1的数据就变成两条数据。
这两条数据一个范围属于服务2,一个属于范围服务组3,其他都一样,也就是牺牲了计算资源,保证整个计算数据都是不相关的,这个其实是有优化空间的,大家可以自己考虑。
到这里多维度采集&计算基本功能点介绍完了。下面就介绍下稳定性的考虑了。
此处有图:
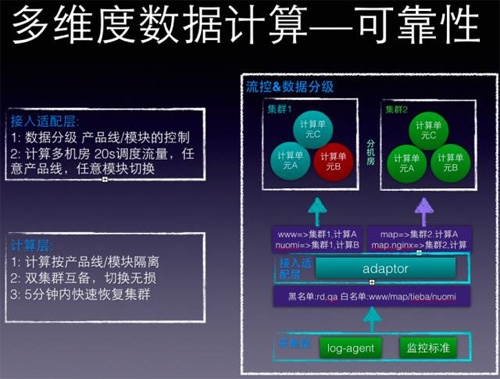
前面一直强调数据符合28定律,所以这个系统首先要支持流控,支持按数据重要性做优先级处理,有如下措施:
***,接入adaptor层,实现按产品线作为流控基本单元,和使用统计,谁用的多就必须多出银子,通过设置黑白名单,当出现紧急情况下,降级处理。
第二,聚合计算做成整个无状态,可水平扩展,多机房互备,因为kafka+storm不敢说是专家,所以在应用架构上做了些文章,主要为:
数据按照名字服务的范围圈出来后,我们发现,只要保证圈出来的“同一范围”的数据保证在同一个计算单元计算,就没有任何问题。
比如建立两个机房集群1,2,每个机房建立3个kafka topic/ storm计算单元,取名为A,B,C计算单元,通过adaptor,将接收的数据做映射,可以有如下映射:
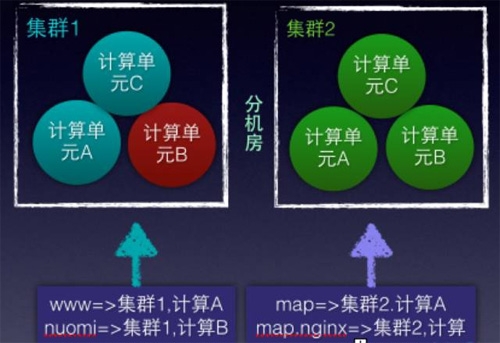
比如地图产品线的接入服务,命名为:map.nginx,只要范围map.nginx的数据映射到一个计算单元即可,可以用如下规则:map.nginx接入 => 集群2,1计算单元A
这样所有map的接入nginx数据就直接将数据写入到集群2机房的A计算单元来完成,集群2的计算单元B挂了,当然不会影响map.nginx。
总结来说,整个计算都是无状态,可水平扩展;支持流控,当有异常时,可以进行双机房切换,如果有资源100%冗余,如果没有,就选择block一些产品线,服务降级。
到这里,整个多维度监控采集和计算介绍完成了:)下面说一下总结和展望吧!

采集就是一个标准化的过程,文本用命名正则其实是无奈之举,期望是pb日志,这样不会因为日志变动导致正则失效,而且性能也会提升;APM也是一样,这个类似于lib的功能,不用通过日志能采到核心数据。
个人很看好pb日志,如果能够有一个通用的pb模板,有一个pb日志的规范推得好,那么还是很有市场的,以后只要这么打日志,用这个模板的解析,就能得到很多内部的数据,不用写正则。
采集就是一个标准之争的权衡,估计你不会骂linus大神为啥把进程监控信息用文本放在/proc/pid/stat,而且进程名为啥只有16个字节;标准就在那,自己需要写agent去将这个标准转换为你内部的标准。
当你自己推出了监控标准,在公司内部用的很多的时候,RD/op需要努力的去适配你了,他们需要变换数据格式到监控标准上;所以,到底是谁多走一步,这个就需要看大家做监控的能力了:)
聚合计算的考虑则是各种算子的丰富,比如uv,还有就是二次计算,就是在storm计算的数据之上,再做一次计算;比如服务=>服务组的上卷操作可以通过二次计算来完成。
比如服务组包含了服务1、服务2,那么我们可以先只计算服务1、服务2的pv数据,然后通过二次计算,算出整个服务组的pv数据 ,由于二次计算没有大数据压力,可以做的支持更多的算子,灵活性,这个就不展开了。
我总结一下:
1.28定律,监控需要倾斜资源处理“关键”指标数据。
2.关键指标数据需要多维度观察,1点变多点,这些数据是相互关联,需要进行meta和配置管理。
3.系统设计时,数据模型先行,功能化、服务化、层次化、无状态化。
4.对开源系统的态度,需要做适配,尽可能屏蔽开源细节,除了啃源码之外,在整个应用架构上做文章,保证高可用性。
答疑环节
1.抓取数据的时候需要客户端装agent?必须要agent吗?
从两方面回答这个问题吧!首先系统设计的是层级化的,你可以不用agent,直接推送到我们的计算接入层;其次,如果你的数据需要采集,那么就是一个标准化的适配过程,比如你的监控数据以http端口暴露出来,那么也需要另一个人去这个http端口来取,手段不重要,重要的是你们两个数据的转换过程,所以不要纠结有没有agent,这个事情谁做都需要做。
2.采集之后,日志是怎么处理的?
日志采集后,通过命名正则进行格式化,变成k:v对,然后将这些k:v对作为类似参数,直接填写到多维度数据模型里面,然后发给聚合计算模块处理。相当于对日志里面相同的字段进行统计,上面说的比如地图nginx日志的处理就是这样。
3.elesticsearch+logstash百度有木有在用呢?还有kafka在百度运维平台中的使用是什么状态呢?
ELK在小产品线有使用,这个多维度监控可以大部分的情况下替换ELK,而且说的自信点,我们重写的agent性能快logstash十倍,而且符合我们的配置下发体系,整个运维元数据定义等;kafka在刚刚的系统里面就是和storm配合作为聚合计算的实现架构。
但我想强调的是,尽量屏蔽开源细节,在kafka+storm上面我们踩过不少坑。通过上面介绍的这种应用框架,可以保证很高的可靠性。
4.多维度数据监控在哪些场景会用的到,可以详细说下几个案例吗?
我今天讲的是多维度数据监控的采集和计算,没有去讲这个应用,但可以透露一下,我们现在的智能监控体系都是在刚刚讲的这一套采集&计算架构之上;每层都各司其职,计算完成后,交给展示/分析一个好的数据模型,至于在这个模型上,你可以做根因定位,做同环比监控,这个我就不展开了。
5.能介绍百度监控相关的数量级吗?
这个就不透露了,但大家也都知道BAT三家的机器规模了,而且在百度运维平台开发部门,我们的平台是针对百度所有产品线;所以,有志于做大规模数据分析处理的同学,你肯定不会失望(又是一个硬广:)
6.不同产品线的聚合计算规则是怎么管理的。不同聚合规则就对应这不同的bolt甚至topology,怎么在storm开发中协调这个问题?
看到一个比较好的问题,首先我们设计的时候,是通用聚合计算,就计算sum/count/avg/min/max分位值,常见的运维都可以涵盖;我们通过agent做了公式计算,表达能力也足够了,同时有二次计算。不一定非要在storm层解决。
我提倡“正确的位置解决问题”,当然大家对这个正确位置理解不同。
7.topology无状态这句话没太明白。storm topology的状态管理不是自身nimbus控制的吗?百度的应用架构在此做了哪些工作或者设计?
我说的是写的storm算子是无状态的,整个数据都是自包含的,我们在应用架构上,就是控制发给stormtopology的数据;多机房互备等;我说的应用架构师在这个storm之上的架构。相当于我认为整个storm topology是我接入adaptor层的调度单元。














