自动化持续部署是业界最佳实践,以此为目标,能优化IT模式。
在接触的很多企业中,持续部署实践依然还有很多不足,基本上部署靠人,更别谈自动化了。我一直强调持续部署是IT交付的核心能力,直接关联到研发/测试和运维多个团队,可以成为一个运维的核心平台。自动化部署能力的高与低,能映射出IT能力的诸多方面的问题,比如说流程上/环境管理上/服务耦合上/平台能力上等等。
个人已经做了三个持续部署系统,每做一个持续部署系统都给整个IT团队带来巨大的收益。当带着这些经历再回过头去看《持续交付》这本书的时候,书中的很多观点让我感触很多,基本上每个点都有自己的感受。
让我们来看看《持续交付》中总结的很多错误的模式,这些错误的模式的确是现实存在的,且必须要避免的,称之为反模式,具体如下:
一、反模式1:手工部署软件
对于现在的大多数应用程序来说,无论规模大小,其部署过程都比较复杂,而且包含很多非常灵活的部分。许多组织都使用手工方式发布软件,也就是说部署应用程序所需的步骤是独立的原子性操作,由某个人或某个小组来分别执行。每个步骤里都有一些需要人为判断的事情,因此很容易发生人为错误。即便不是这样,这些步骤的执行顺序和时机的不同也会导致结果的差异性,而这种差异性很可能给我们带来不良后果。这种反模式的特征如下:
◆有一份非常详尽的文档,该文档描述了执行步骤及每个步骤中易出错的地方。
◆以手工测试来确认该应用程序是否运行正确。
◆在发布当天开发团队频繁地接到电话,客户要求解释部署为何会出错。
◆在发布时,常常会修正一些在发布过程中发现的问题。
◆如果是集群环境部署,常常发现在集群中各环境的配置都不相同,比如应用服务器的连接池设置不同或文件系统有不同的目录结构等。
◆发布过程需要较长的时间(超过几分钟)。
◆发布结果不可预测,常常不得不回滚或遇到不可预见的问题。
◆发布之后凌晨两点还睡眼惺忪地坐在显示器前,绞尽脑汁想着怎么让刚刚部署的应用程序能够正常工作。
相反,随着时间的推移,部署应该走向完全自动化,即对于那些负责将应用程序部署到开发环境、测试环境或生产环境的人来说,应该只需要做两件事:(1)挑选版本及需要部署的环境;(2)按一下“部署”按钮。对于套装软件的发布来说,还应该有一个创建安装程序的自动化过程。
当然,并不是所有的人都热衷于这个想法。那么,我们先来解释一下为什么把自动化部署看做是一个必不可少的目标。
◆如果部署过程没有完全自动化,每次部署时都会发生错误。唯一的问题就是“该问题严重与否”而已。即便使用良好的部署测试,有些错误也很难追查。
◆如果部署过程不是自动化的,那么它就既不可重复也不可靠,就会在调试部署错误的过程中浪费很多时间。
◆手动部署流程不得不被写在文档里。可是文档维护是一项复杂而费时的任务,它涉及多人之间的协作,因此文档通常要么是不完整的,要么就是未及时更新的,而把一套自动化部署脚本作为文档,它就永远是最新且完整的,否则就无法进行部署工作了。
◆自动部署本质上也是鼓励协作的,因为所有内容都在一个脚本里,一览无遗。要读懂文档通常需要读者具备一定的知识水平。然而在现实中,文档通常只是为执行部署者写的备忘录,是难以被他人理解的。
◆以上几点引起的一个必然结果:手工部署过程依赖于部署专家。如果专家去度假或离职了,那你就有麻烦了。
◆尽管手工部署枯燥且极具重复性,但仍需要有相当程度的专业知识。若要求专家做这些无聊、重复,但有技术要求的任务则必定会出现各种我们可以预料到的人为失误,同时失眠,酗酒这种问题也会接踵而至。然而自动化部署可以把那些成本高昂的资深高技术人员从过度工作中解放出来,让他们投身于更高价值的工作活动当中。
◆对手工部署过程进行测试的唯一方法就是原封不动地做一次(或者几次)。这往往费时,还会造成高昂的金钱成本,而测试自动化的部署过程却是既便宜又容易。
◆另外,还有一种说法:自动化过程不如手工过程的可审计性好。我们对这个观点感到很疑惑。对于一个手工过程来说,没人能确保其执行者会非常严格地遵循文档完成操作。只有自动化过程是完全可审核的。有什么会比一个可工作的部署脚本更容易被审核的呢?
◆每个人都应该使用自动化部署过程,而且它应该是软件部署的唯一方式。这个准则可以确保:在需要部署时,部署脚本就能完成工作。我们会提到多个原则,而其中之一就是“使用相同的脚本将软件部署到各种环境上”。如果使用相同的脚本将软件部署到各类环境中,那么在发布当天需要向生产环境进行部署时,这个脚本已经被验证过成百上千次了。如果发布时出现任何问题的话,你可以百分百地确定是该环境的具体配置问题,而不是这个脚本的问题。
当然,手工密集型的发布工作有时也会进行得非常顺利。有没有可能是糟糕的情况刚巧都被我们撞见了呢?假如在整个软件生产过程中它还算不上一个易出错的步骤,那么为什么还总要这么严阵以待呢?为什么需要这些流程和文档呢?为什么团队在周末还要加班呢?为什么还要求大家原地待命,以防意外发生呢?
二、反模式2:开发完成之后才向类生产环境部署
在这一模式下,当软件被第一次部署到类生产环境(比如试运行环境)时,就是大部分开发工作完成时,至少是开发团队认为“该软件开发完成了”。这种模式中,经常出现下面这些情况:
◆如果测试人员一直参与了在此之前的过程,那么他们已在开发机器上对软件进行了测试。
◆只有在向试运行环境部署时,运维人员才第一次接触到这个新应用程序。在某些组织中,通常是由独立的运维团队负责将应用程序部署到试运行环境和生产环境。在这种工作方式下,运维人员只有在产品被发布到生产环境时才第一次见到这个软件。
◆有可能由于类生产环境非常昂贵,所以权限控制严格,操作人员自己无权对该环境进行操作,也有可能环境没有按时准备好,甚至也可能根本没人去准备环境。
◆开发团队将正确的安装程序、配置文件、数据库迁移脚本和部署文档一同交给那些真正执行部署任务的人员,而所有这些都没有在类生产环境或试运行环境中进行过测试。
◆开发团队和真正执行部署任务的人员之间的协作非常少。
每当需要将软件部署到试运行环境时,都要组建一个团队来完成这项任务,有时候这个团队是一个全功能团队,然而在大型组织中,这种部署责任通常落在多个分立的团队肩上。
#p#
一旦将应用程序部署到了试运行环境,我们常常会发现新的缺陷。遗憾的是,我们常常没有时间修复所有问题,因为最后期限马上就到了,而且项目进行到这个阶段时,推迟发布日期是不能被人接受的。所以,大多数严重缺陷被匆忙修复,而为了安全起见,项目经理会保存一份已知缺陷列表,可是当下一次发布开始时,这些缺陷的优先级还是常常被排得很低。
有的时候,情况会比这还糟,以下这些事情会使与发布相关的问题恶化:
◆假如一个应用程序是全新开发的,那么第一次将它部署到试运行环境时,可能会非常棘手。
◆发布周期越长,开发团队在部署前作出错误假设的时间就越长,修复这些问题的时间也就越长。
◆交付过程被划分到开发、DBA、运维、测试等部门的那些大型组织中,各部门之间的协作成本可能会非常高,有时甚至会将发布过程拖上“地狱列车”。此时为了完成某个部署任务(更糟糕的情况是为了解决部署过程中出现的问题),开发人员、测试人员和运维人员总是高举着问题单(不断地互发电子邮件)。
◆开发环境与生产环境差异性越大,开发过程中所做的那些假设与现实之间的差距就越大。虽然很难量化,但我敢说,如果在Windows系统上开发软件,而最终要部署在Solaris集群上,那么你会遇到很多意想不到的事情。
◆如果应用程序是由用户自行安装的(你可能没有太多权限来对用户的环境进行操作),或者其中的某些组件不在企业控制范围之内,此时可能需要很多额外的测试工作。
三、反模式3:生产环境的手工配置管理
很多组织通过专门的运维团队来管理生产环境的配置。如果需要修改一些东西,比如修改数据库的连接配置或者增加应用服务器线程池中的线程数,就由这个团队登录到生产服务器上进行手工修改。如果把这样一个修改记录下来,那么就相当于是变更管理数据库中的一条记录了。这种反模式的特征如下:
◆多次部署到试运行环境都非常成功,但当部署到生产环境时就失败。
◆集群中各节点的行为有所不同。例如,与其他节点相比,某个节点所承担的负载少一些,或者处理请求的时间花得多一些。
◆运维团队需要较长时间为每次发布准备环境。
◆系统无法回滚到之前部署的某个配置,这些配置包括操作系统、应用服务器、关系型数据库管理系统、Web服务器或其他基础设施设置。
◆不知道从什么时候起,集群中的某些服务器所用的操作系统、第三方基础设施、依赖库的版本或补丁级别就不同了。
◆直接修改生产环境上的配置来改变系统配置。
运维的关键实践之一就是配置管理,其责任之一就是让你能够重复地创建那些你开发的应用程序所依赖的每个基础设施。这意味着操作系统、补丁级别、操作系 统配置、应用程序所依赖的其他软件及其配置、基础设施的配置等都应该处于受控状态。你应该具有重建生产环境的能力,最好是能通过自动化的方式重建生产环境。
我们也应该有能力在部署出错时,通过同一个自动化过程将系统回滚到之前的版本。
四、问题的答案:自动化部署
实现一个完善的自动构建、部署、测试和发布系统。为了让这个系统能够良好运行下去,我们还帮助他们采用了一些必要的开发实践和技术(大系统做小/维服务/灰度能力等等)。如何使用部署流水线,将高度自动化的测试和部署以及全面的配置管理结合在一起,实现一键式软件发布。也就是说,只需要点击一下鼠标,就可以将软件部署到任何目标环境,包括开发环境、测试环境或生产环境。
——————以上观点摘自《持续交付》
见到的通行做法是三种:
1.自动化脚本来封装,用expect+ssh;
2.用配置管理工具来实现;
3.在Jenkins中写插件来实现。
但我依然觉得,这不是我要的可视化+自动化部署系统,一般都选择自己实现。
1.YY包部署系统
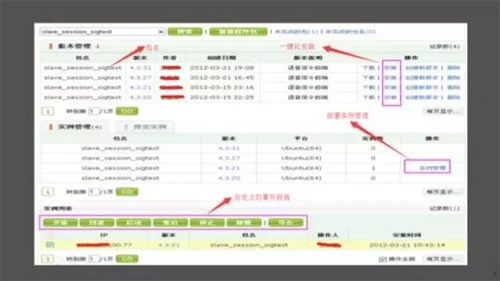
缺点:
A、对配置管理支持的不是很好
B、环境管理能力很弱
C、没有以应用维度进行管理
2.UC的持续部署系统
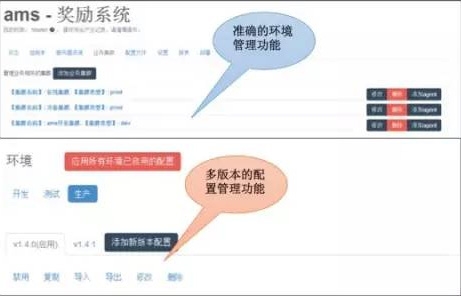
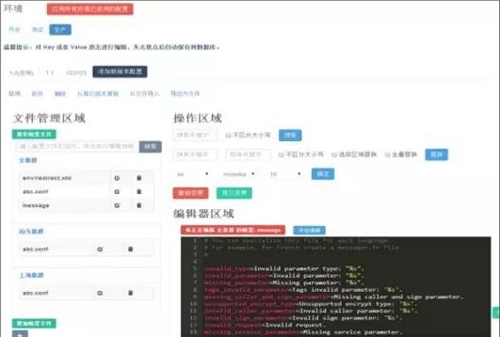
这是利用公司另外一个系统基础上修改过来的,支持了游戏业务的特殊发布场景,做了一些优化,但还是有一些缺点。
缺点:
A、应用程序和底层Agent的耦合太重,Agent的异常会影响应用程序的工作。
B、系统架构设计很复杂,涉及组件过多,基于CF修改过来的。
C、基于CF的PAAS平台每支持一种语言就要重新开发。
D、对于包的抽象能力不够,管理能力需要在Agent层封装。当然这个能力可以更上层实现,兼容各种操作场景。
3.新持续部署系统(doing)
基于包的全新抽象,支持各种语言;开放包的管理能力给用户,适应各种场景;支持对包/配置/环境的可视化管理;支持灰度,支持快速回滚....等等。