追求极致IT性能的运维是精益运维的高度体现!
在复杂的IT运维组织事务活动中,如何确定IT运维的目标,对于很多运维组织来说也是一个难点。有些运维组织用的是稳定性/可用性/质量的指标,有些团队用的是效率,有些团队用的成本指标等等。说实话,在以上诸多指标中,能够带来巨大变革力和牵引力的,我个人认为还是效率,或者是性能,就是完成某个事情有多快。但很多时候,需要对这个IT性能形成精确的理解,才能形成真正的作用力。
有人会说,为什么运维的核心目标不是追求业务的稳定性/可用性/质量呢?我个人一直秉承的观点,这些指标根本不是运维人的核心职责,而是开发、 测试和运维共同的核心职责。记得Jez Humble说过,“测试者并不能增加产品的质量,而只是让质量透明出来,更直接的说测试是为了确认软件是否可部署”。而戴明在谈质量管理的时候,更是直 接了当的说“停止事后检验来达到高质量的依赖,应该在产品之初就开始考虑质量”。其实类推到我们运维过程也是同样如此,软件不能靠后期的运维来达到业务的 高质量,而更应该把运维作为早期软件设计过程的一部分。
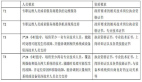
我们讲要追求IT性能,这个也是来源早期的一个管理思想---精益思想。精益思想的五个原则所蕴含的内在核心就是“拒绝浪费,创造价值”,从一开始就要求从客户的角度来定义产品价值(满足某类功能或者服务的需求),通过这一价值的定义,再反向推导出内部的价值活动流,比如说需求设计、概要设计、详细设计、软件研发、测试、运维等等。拉动式价值的创造过程是一种让客户的价值诉求决定内部活动的价值创造,是一种精益式做法,是有目标的行事。持续改进 式到完美状态,其实这个从软件研发传统的瀑布模型到敏捷模型,再到DevOps模型,目的都是让软件创作的多个职能组很好的衔接起来,而不产生停滞的状 态。这个地方更需要提到的是持续集成,它是实现精益的一个有效手段,落地的最佳方式。这一思想的背后,无不透露着对性能、对质量的极致要求,比如说等待就 是一种精益思想所理解下的性能浪费。
从软件交付的角度来说,运维是离用户最近的,那么运维的IT性能和整个IT组织的性能息息相关,另外运维要把IT性能要求反向传导研发、测试过程,催其持续改进。而对IT性能的核心的识别原则,就是从用户的角度来设置指标。其实本质上来说,IT性能的核心指标是吞吐率和延时,但这两个指标需要和用户价值流进一步去关联。进一步分解,就可以形成如下的指标体系:
(一)服务交付的延时
延时就是看完成一次服务交付要多长时间。这个地方的场景就很多了,核心的就两类场景:
第一、持续的软件新功能和新特性交付过程,应用发布的过程,处理的粒度是应用,和研发、测试过程密切相关。这个就是当前持续集成思考的范畴。
第二、因为容量、服务搬迁等原因,面向用户的整体服务的交付过程,比如说用户访问量增加,扩容数据库,扩容前端,扩容某个组件等等,这个聚焦在运维内部过程就可以了,无须软件设计、软件研发过程的接入,纯运维的输出。以下就是一个完整的服务上线过程图:

(二)服务交付的频率
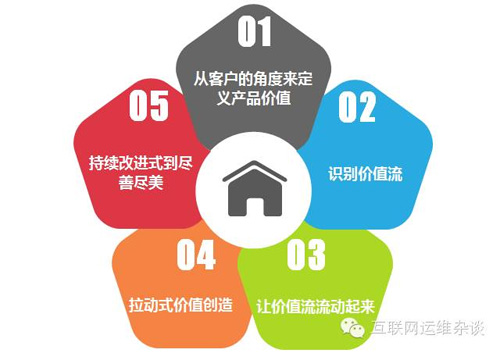
频率可以算是单位周期内的交付能力。一个典型的场景就是每个月持续部署的数量,由此折算出交付的频率怎么样。以下是我们当前游戏持续部署平台的交付能力,有了平台之后对人的依赖大大的降低,同时吞吐率大大提升。
而刚刚说的整体服务交付过程,可以由自己的业务调度变更平台输出,这个地方重点关注批量作业的能力,比如说一个变更单能扩容多少台,花费时间多少?这种往往是用户需求拉动的,所以对他的频率考察要求就不是太高了。
(三)故障恢复的延时
故障恢复的延时直接会影响服务的可用性,影响用户对产品质量的感知。服务恢复的越快,就说明运维故障处理能力越强。在进一步细分故障处理能力的过程,可以分解成三个部分:故障发现、故障定位、故障处理与解决。这三部分都直接考察了运维的能力,这三部分能力可以直接的映射到监控系统上。故障发现是需要监控系统要走向基于用户的实时监控上去;故障定位是需要监控系统能够打通基于用户流的数据能力;故障处理是需要运维人工的处理经验沉淀,然后再自动 化。
有了如上的核心指标之后,那么我们就需要同步思考那些因素会影响IT性能,这些点就需要后续持续的改进。个人也总结了一些自己看到的点:
(四)建立开发与运维之间的互信
开发一定不要把运维当做一个简单的资源提供者角色来看待,需要准确的看待运维的价值。只有运维才有能力从所有业务的角度出发,构建统一的IT服务平台提供给业务使用,对于公司来说,也是一种降低浪费的方式。开发和运维之间的互信、合作以及责任共享的团队氛围是高性能运维团队的基础,缺少研发、测试的支持,运维只能在低级层次上做服务封装,而缺少对运维的深层次理解。
(五)团队的多样性
对于运维团队来说,首先需要保证运维研发和运维执行者角色搭配,但需要有一种机制就是运维执行者需要不断的把需求转换到运维研发团队,让他提供平台性的实现,甚至运维执行者自己也需要尝试转变,使自己具备运维研发的能力。其次对于团队来说,需要有个阶梯性,都是运维执行不行,都是运维研发也不行,都是运维技术性高手也不行,需要有推动能力强的,技术能力强的和运维研发能力强的搭配等等;最后运维团队需要有女性角色存在,当然你不能把她当男人使用,这样你的团队就缺少了柔性。
(六)可视化运维过程
我觉得没有比可视化的要求更能驱动运维的过程。但你想着要可视化的时候,一定想着如何简化你的运维过程,否则实现起来非常的繁琐。可视化,是运维把问题化繁为简、把思路从模糊变清晰、把工具变产品的一个过程。
(七)持续交付(持续集成+持续部署)
这是敏捷业务形态下的标配了,更是互联网业务的一个标配。但对于传统业务来说,实施持续交付貌似还有一点难度,很大一部分和服务耦合有关系。做互联网不可能不知道Jenkins,不可能不知道持续部署。具体的最佳实践请参照【持续集成】那本书,里面写了很多最佳的实践标准。
(八)一键化调度平台
通过该平台来解决整体服务交付的能力问题,一键化调度平台需要打通所有的运维内部服务,把所依赖的运维服务和技术架构服务抽象成一个个API供其调用。此时需要对线上服务环境做一些标准化的约束,比如说服务之间的调用抽象到名字服务中心,应用环境对系统环境零依赖等。线上技术架构的运维管理应该Api服务化,可以通过API来控制技术架构中的服务,比如说配置文件管理/组件服务管理/服务降级服务/服务过载保护设置等等。越API化,意味着机器能够控制的能力越强,也就意味着运维性能能力可以越高。
(九)端到端的监控平台
监控在故障恢复延时中起到核心作用,需要化运维被动监控变为主动监控。从用户的角度实现主动式的监控才是真正的监控系统发现问题的有效手段,而非传统的监控系统从系统内部指标看问题。端到端,从用户侧到服务侧,基于应用的拓扑完成整个数据通路的构建。
还有一个因素要特别注意,就是架构的智能决策能力。在个人推动SDK双中心的时候,当我们设定服务故障恢复时长为8分钟,发现真正的系统恢复能力不是靠人,而是让后台故障被前台感知,从而让前台实现智能决策,屏蔽故障节点。这样的例子比比皆是,mysql的故障由proxy来屏蔽决策;proxy的故障由名字服务来调度屏蔽;名字服务的故障实现高可用,不依赖中心节点;逻辑层故障也由名字服务中心来调度屏蔽;web层故障由负载均衡层调度屏蔽;负载均衡层故障由DNS或者httpdns调度屏蔽。
IT性能,应该成为运维团队的核心驱动力,它能够直接反映运维能力水平。运维对IT性能的极致苛求,也直接反映了运维团队自我价值要求,甚至也决定了运维团队的能力建设。没有IT性能最强的运维团队,只有IT性能更强的运维团队。它如同优化线上的业务程序一样,运维团队的性能优化也永远没有终点。