最近决定将以前同事写的存储过程查看一遍,寻找一些代码上写的不太好的地方,争取进行修改以后让这些过程达到一个很好的运行速度。下面是遇到的最多的几个问题。
我遇到了这样的一个SQL:
select name, count(*) from (select name from table_1) a group by a.name;
MySQL的执行计划对于这种派生表的解释非常的不友好,但是能直观的感觉到的是,这个SQL执行速度特别的慢。查看这个表table_1发现,name字段是有索引的。审视这段代码,可以推断出当时程序员的想法,应该是想让数据库扫描更小的结果集,因为select *是很不好的习惯。不过他应该忽略了一个MySQL的很重要的特点就是索引。MySQL的索引是个很有意思的东西,是我从Oracle转过来感觉***玩的东西,好玩的地方就在于,可以优化group by。当我把这个SQL改成如下SQL以后:
select name, count(*) from table_1 group by name;
这样一来,这段SQL的执行速度就非常的快了,extra列明确的显示了using index,索引覆盖查询,速度杠杠的。
其实这种错误应该是程序员常犯的,因为程序员对Java等代码超级熟悉,但是对于SQL,基本上都是大学的时候学习的SQL,用SQLServer练出来的,基本上没有对数据库进行非常深入的研究,其实每种数据库中,同一条SQL的执行计划都是不尽相同的,这也就是企业有一个专业的DBA的一个作用。
下面,就是一个让人很头疼的错误:
select name, userid from table_1 where name = null;
不管是MySQL还是Oracle,对这种SQL的写法的规范都是where name is (not) null。null这个值,在不管什么数据库里都是一个让人(包括程序员和DBA)都很头疼的东西。我对MySQL的理解还不够深入,但是根据某一本《Oracle DBA手记》中记载,Oracle中每种数据类型的null都代表了不一样的意义。
做了下面一个实验:
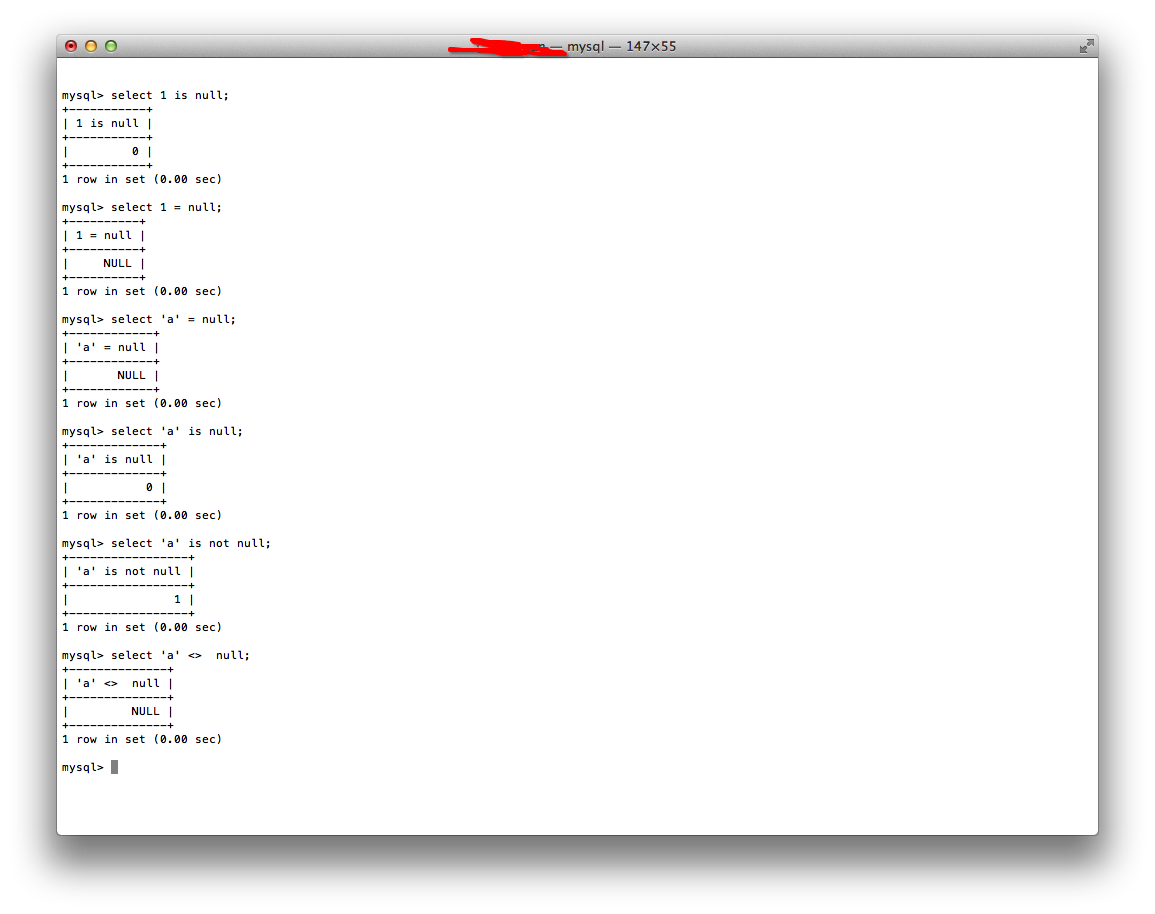
可以看出来,不管是“= null”还是“<> null”,得到的值其实都是不确定,也就是null。因此,必须要写成is (not) null。在《剑破冰山》这本书里也有对Oracle的null值的详细介绍。
总结一下最近的工作,我研究了小半年时间的MySQL,发现这个开源的数据库并不像我过去认为的那样,就是一个互联网数据库。这个数据库在面向OLAP复杂计算的方面确实和Oracle,DB2等商用数据库之间有不小的差距,不过在MariaDB这个分支中,这部分有了不小的进步,相信后面的MySQL版本中也会越来越好。其实这个数据库最让我感兴趣的不是开源,因为我确实看不懂那么长的源代码,我的C语言水平就是大学毕业水平。这个数据库最让我感兴趣(起码现在来讲)是它的索引,它的索引和Oracle有很大的不同,尤其是InnoDB的表整个就是用索引组织起来的,在简单的查询的时候,一个索引覆盖查询就可以无敌于天下了,在group by和order by的时候,如果是索引字段,效率会相当的高。
其实我还想说的就是,一个团队里,如果涉及到大量存储过程的编写,一定要有一个专业的DBA人员参与其中。SQL是一个标准,横跨了所有的关系型数据库,但是每一种关系型数据库对SQL的实现又不尽相同,因此同样的一段SQL,放到不同的数据库上执行,效率上就会千差万别。而SQL又非常容易用人最习惯最简单的思维写出来,比如搜索一个订单表里美国员工生成的订单信息,SQL有可能是这样的:
select * from orders t1 where t1.employee_id in (select employee_id from employee t2 where t2.nation = 'USA');
如果是Oracle这样的商业数据库,这个SQL的执行效率可能会比较好,但是应该不如用exists的SQL。但是当这段SQL在MySQL中执行的时候,效率就很差了,因为很多人都知道,MySQL的子查询效率实在是不敢恭维。这段代码会被改为相关子查询,而且随着数据量的增长,执行时间会越来越长。这段代码如果改成下面的SQL,效果会更好:
select t1.*
from orders t1
inner join employee t2
on t1.employee_id = t2.employee_id
where t2.nation = 'USA';
如果表上有索引,执行速度快极了。
写SQL,还是要首先研究这个数据库的原理,然后慎而又慎的写。